Real web browsing is harder than benchmarks suggest.
Large language models are increasingly deployed as autonomous agents that interact with the web through browsers. While recent progress has been driven by benchmarks evaluating end-to-end task success, these evaluations largely overlook two fundamental sources of difficulty in real web browsing: complex actions over rich user interfaces and visual perception of dynamically rendered content, especially in workflows that span multiple websites.
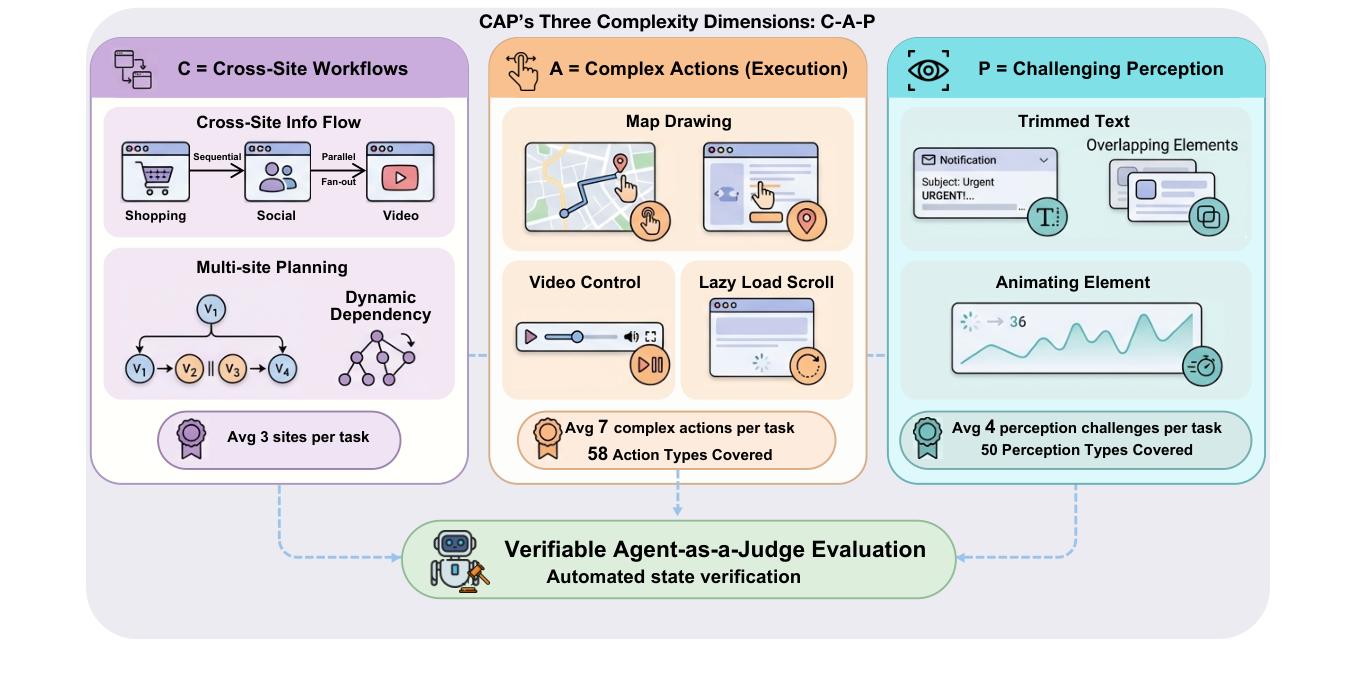
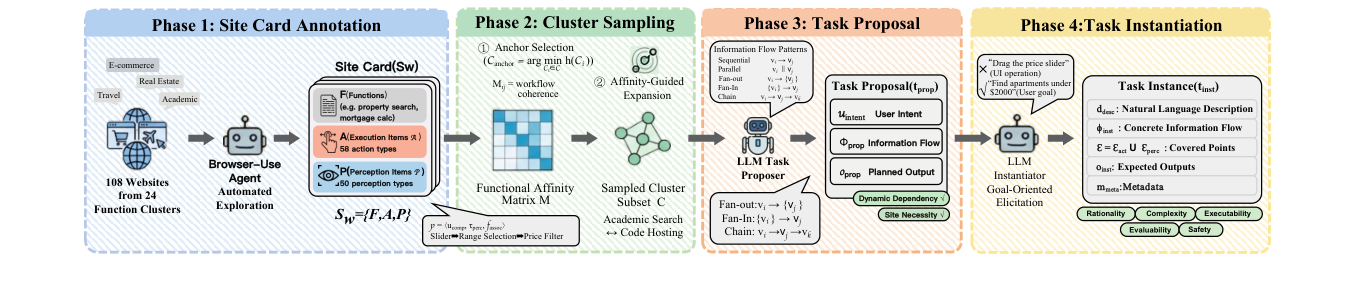
We introduce CAP, a scalable benchmark for browser agents on cross-site, human-like web tasks that require non-trivial UI interactions and visual understanding. We adopt a decomposition-and-recomposition pipeline that abstracts each website into a structured site card capturing user-facing functions, complex execution operations, and perceptual requirements, then recomposes these components into realistic cross-site workflows.
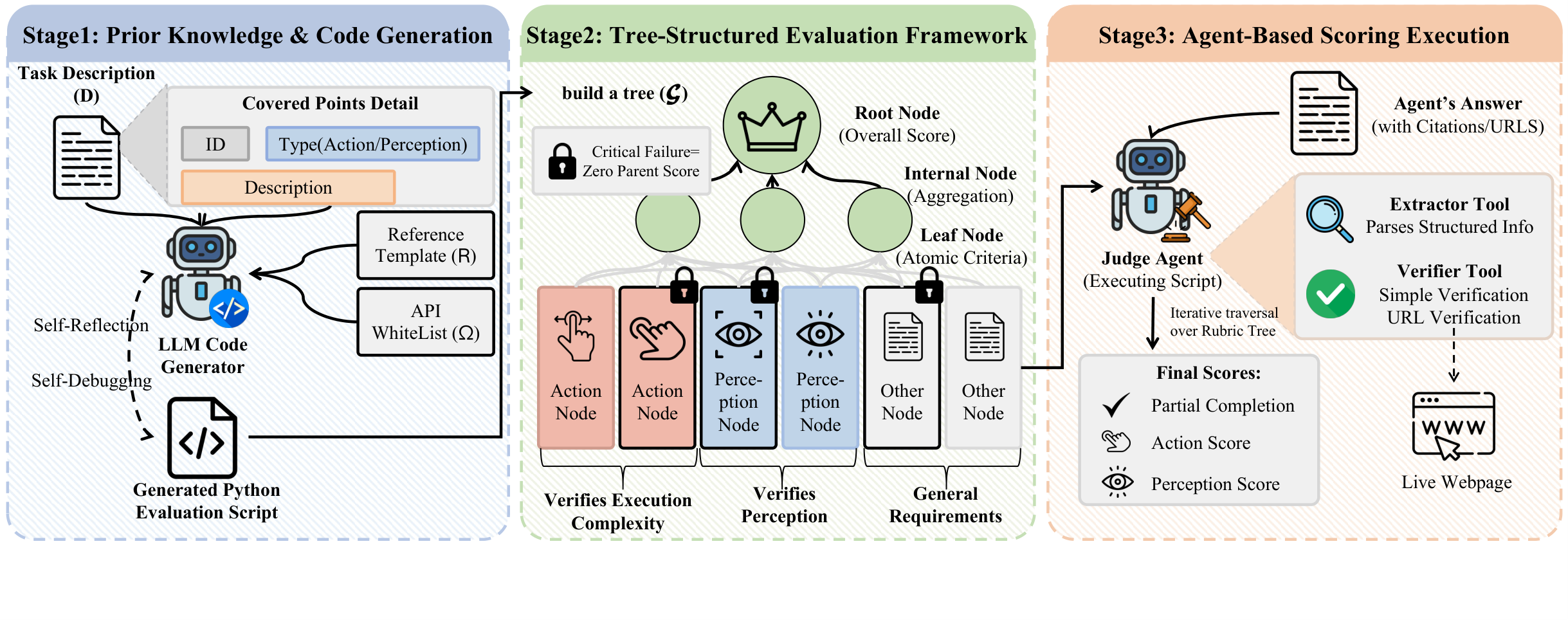
Built on this framework, we construct 420 tasks across 108 real-world websites in 24 domains under careful quality control. Experiments on state-of-the-art browser agents reveal that perception-heavy interactions remain a major bottleneck — exposing substantial gaps between current agents and real-world web browsing demands.
Cross-Site Workflows
Avg 3 sites per task, with sequential, parallel, fan-out and chain information flow.
Complex Actions
Avg 7 complex actions per task. 58 action types — sliders, drag, drawing, video control.
Challenging Perception
Avg 4 perception challenges per task. 50 types — charts, lazy-load, animating elements.